Make sure your data is up to date in bigquery
Table of Contents
Introduction
In my work, data pipelines are nesscesary in order to provide clients with the correct data. unfortunately sometimes due to changes in the API, access being removed, or unexpected timeouts and crashes ends up having the data not being updated properly meaning that the marketing automation systems and dashboards are not updated.
We almost store all relevant data in BigQuery, while the same data can be pushed to many other platforms such marketing automation systems, SQL databases etc. Because of this, we can utilize the metadata from BigQuery and see if the datasets are updated at the right time.
At the moment the data is compiled to an R markdown document which makes anyone in our BI team to easily see if the data is up to date, should something be wrong, but use it in any way you see fit.
The service account key
I could spend a few hours writing down how to create a service account key in the Google Cloud Platform, however I think it would be smarter to link it right here instead: https://cloud.google.com/iam/docs/creating-managing-service-account-keys
Once it is created, put it in the directory you are working on in R, and open it up. It should look like this:
{
"type": "service_account",
"project_id": "youproject",
"private_key_id": "keyid1+239123",
"private_key": "-----BEGIN PRIVATE KEY-----\nadfsdfsdfdsfdsfsdfaenIkd\nTVaeeeOZIODyN3ZYWxLwersffsdfdsb4we71lbHrg\nkJwHn8osrhssgfhCxp8y15YV8jrDof+TChTDe5wIj5WPvJO8\ndyBFchZx0ptbakmPb/ybeU7gKi3yPO29Mgoz4Cb47gNPvuZX82ic3dYE7YMEO1VF\nyfc1zHF6UJEAdrMSe+YO5oiGABemGj8FTNb+0Q0XurC4da3Qvwmz43OaICNTGzgI\nmkHB6fqsvSSVDi0agPE68wVGIDSEew9kEGUeAMw/e+T7NIY8z2PYJ5Dv6RWj/+b9\nh1XHiEwBAgMBAAECggEAISrTAqBfXFX966X8CVPjd3C198Yn/oyMssdfdsfdsÅQelFF\nJKxAt/Pnyr2xDYZLWgK3QChYibhufCwHq6V7BiWSO7F2PluuJedr9scG7u+t5se7\nr7gpyhTZIxljRsfdgsfgmEGDQz1wVpYnghySNHIHSWQcRG\nARYkv9v9LmwStA20Tr3BGEa1t3GF+4DAnW5DIP50TwzHv0wiG0+5vX3bWc+x/NR0\njAJKsDcoMzNtIqieLm7cizjS9Ku+rdHaelN8dt51jVAHATQ4oXwEyA0SpbkaLbqx\nvU+Y4U3plPZ1uAWHAtSI6fsrqOKpWA3g6MHVDiJQKQKBgQDGqbi62wq6vWETzByo\nOoiVvJLszm8iYA7LkgKPsJsfVvd+HJcv7uldL04ZaUIGvZ24shbRLN78Z0AnRzxX\nXZF3Vn64ROfxDSkcYOitipRdxBlsdfgrfbbZqeOvPVSy3qMn1Bqlf\ndFNvEtcMQ6YhRbAjbjgvlgiBTQKBgQC6yseYbmiJyRASBcyXcaguuvoebnn7l8r8\n2S1A7wTt1Sy5iPn1RfmUP4DK09y4zNtRYtNwNhu/VhB20MU8Na9ImKBVuvA3O0Ic\nIUeRFgDI2M3u4rGkLlsfgdgdf7f9oRUhPefGIAcNiqm3SACB2w9T\nuo5yMGIbhQKBgQCSkR7wBLCqysfdgfdgsdfO1X6U4kvCyG8oV1chsdfgfdgO6sSveufbbYGApKhpy2R6fydxNQKBgBHg\nØØØØØkzEA1exc3HfaaB5ayGz5LvLKP5hwe2Lt47HL6TFg\nw9t5Ui59jhXQ5Q9eE+hesvmBanver/UBOlgoQur11L+H8nhD9vEQOLOThyA2xmha\nS6V0sacUQ3Fq+0N6zTH+åååååøøøåå+q4y7JQSQiHd23\n22e4PAfX3Df+8860Axrx6fkImbvKxuOZ+uYpwhYMpPdgvukuAqXCHDcG5Fiho28g\n27JHFzQql0pn9Pj4O+WkUOs0rX9rcPjvV9h6Jc/YEWV6YwXMnEkKRaMj44+x7a69\npPfrTO7pBJAquiiU3dCmVDU=\n-----END PRIVATE KEY-----\n",
"client_email": "yourserviceaccoutname@yourproject.iam.gserviceaccount.com",
"client_id": "12345678910",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/yourserviceaccountname%40yourproject.iam.gserviceaccount.com"
}
Here you need to add the email you see under "client_email": "yourserviceaccoutname@yourproject.iam.gserviceaccount.com" and add that to all the BigQuery projects you want to monitor:
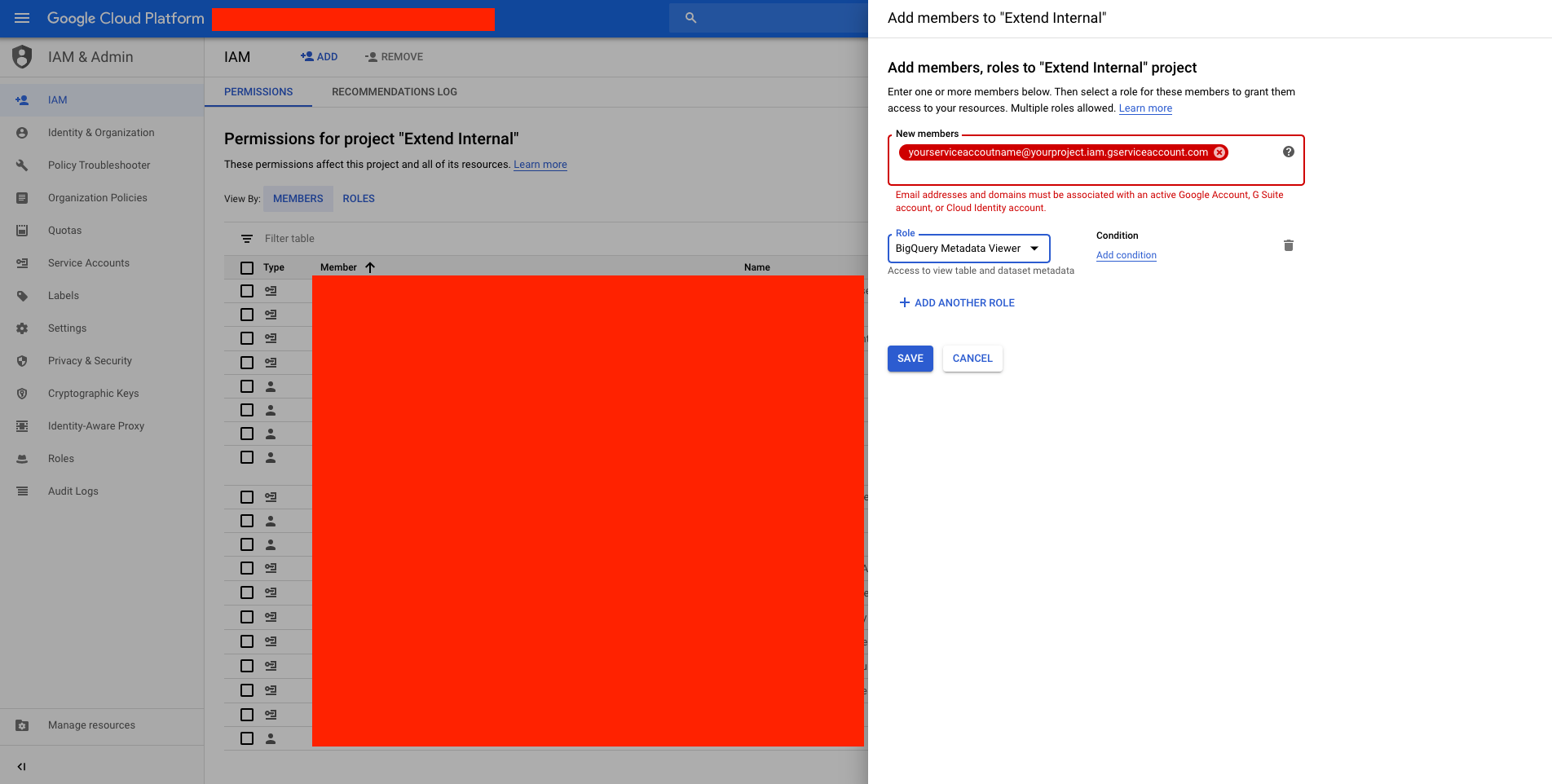
Building the code
1. authenticate and load libraries**
#libraries
library(bigQueryR)
library(purrr)
library(dplyr)
#auth
bigQueryR::bqr_auth("yourauthfile.json")
2. Get a list of all projects and datasets
#get projects
projects <- bigQueryR::bqr_list_projects()
#get datasets
datasets <- lapply(projects$projectId,bqr_list_datasets)
datasets <- bind_rows(datasets)
This will give us two tables that show us all the projects and datasets that the service account have access to. We need this information to list all avaliable tables.
3. Get a list of all tables to extract metadata
#get tables
listTables <- function(id,dataset){
bqr_list_tables(projectId = id,
datasetId = dataset, maxResults = -1)
}
tables <- mapply(listTables,datasets$projectId,datasets$datasetId)
tablesCombined <- bind_rows(tables)
Then we can use these lines in order to extract the metadata:
#get meta
tablesMeta <- function(project,dataset,table){
bqr_table_meta(projectId = project,
datasetId = dataset, table)
}
tablesMeta <- mapply(tablesMeta,tablesCombined$projectId,tablesCombined$datasetId,tablesCombined$tableId)
It can take some time if you have a lot of projects. If you want to speed up the process you can process it with the future package instead to run it in parallel: https://cran.r-project.org/web/packages/future/index.html.
Once it is done, we get a list of which gives us a list of objects with metadata:
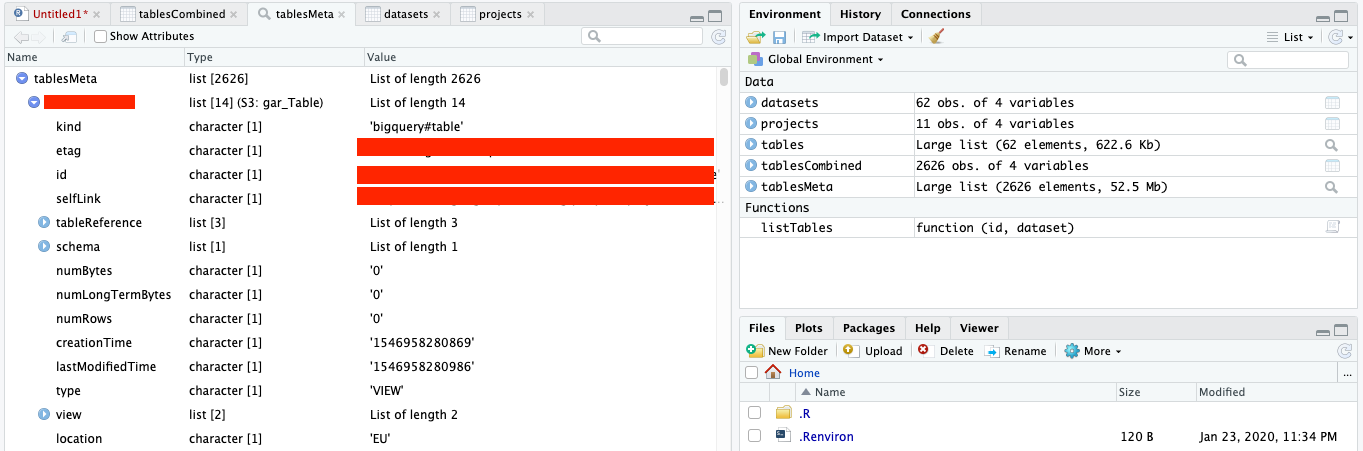
As seen, it isn’t great for working with yet, so we need to take the information we need for each list object and stitch it together in a format that is more fit for working with.
The process will be to:
- Get the number of rows in the listobject
- create an empty dataframe with column names
- extract the data we need for each list
#create a dataframe with the right information for bq
#get the total rows
i <- seq_along(1:NROW(tablesMeta))
#create an empty dataframe with column headers
bqUpdate <- setNames(data.frame(matrix(ncol = 7, nrow = 0)), c("id","projectId","datasetId","creationTime","lastModifiedTime","type","location"))
#create function for looping for appending metadata
combineMetaData <- function(i){
add_row(bqUpdate,
id = tablesMeta[[i]][["id"]],
projectId = tablesMeta[[i]][["tableReference"]][["projectId"]],
datasetId = tablesMeta[[i]][["tableReference"]][["datasetId"]],
creationTime = tablesMeta[[i]][["creationTime"]],
lastModifiedTime = tablesMeta[[i]][["lastModifiedTime"]],
type = tablesMeta[[i]][["type"]],
location = tablesMeta[[i]][["location"]]
)
}
#run the function and combine it
upload <- map(i,combineMetaData)
upload <- bind_rows(upload)
Finally format the table a little, so it is more readable:
upload$creationTime <- format(as.POSIXct(as.double(upload$creationTime)/1000, origin = "1970-01-01", tz = "GMT-1"),"%Y-%m-%d %H:%M:%S" )
upload$lastModifiedTime <- format(as.POSIXct(as.double(upload$lastModifiedTime)/1000, origin = "1970-01-01", tz = "GMT-1"),"%Y-%m-%d %H:%M:%S" )
upload$dataset <- gsub(".*\\.","",upload$id)
upload$daysSinceUpdate <- Sys.Date()-as.Date(as.character(upload$lastModifiedTime), format="%Y-%m-%d")
upload <- upload[order(upload$daysSinceUpdate, decreasing=F),]
The output should look something like this:
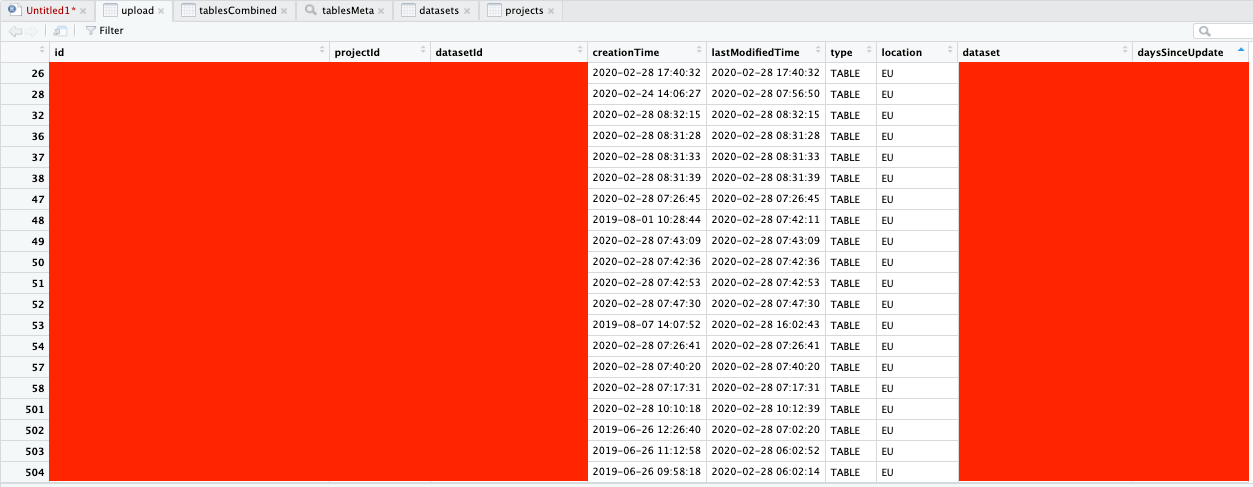
And voila, you now have a list of all your tables in BigQuery, as well as being able to see how many days it is since they were last updated.
Optional R Markdown
In our company, the persons in charge of marketing automation and data visualization, wanted to be able to pinpoint if there should be any issues with having updated data in their systems, as the first thing they look through. I therefore created a R markdown document, that they could use by visiting a page stored in Google Cloud Storage.
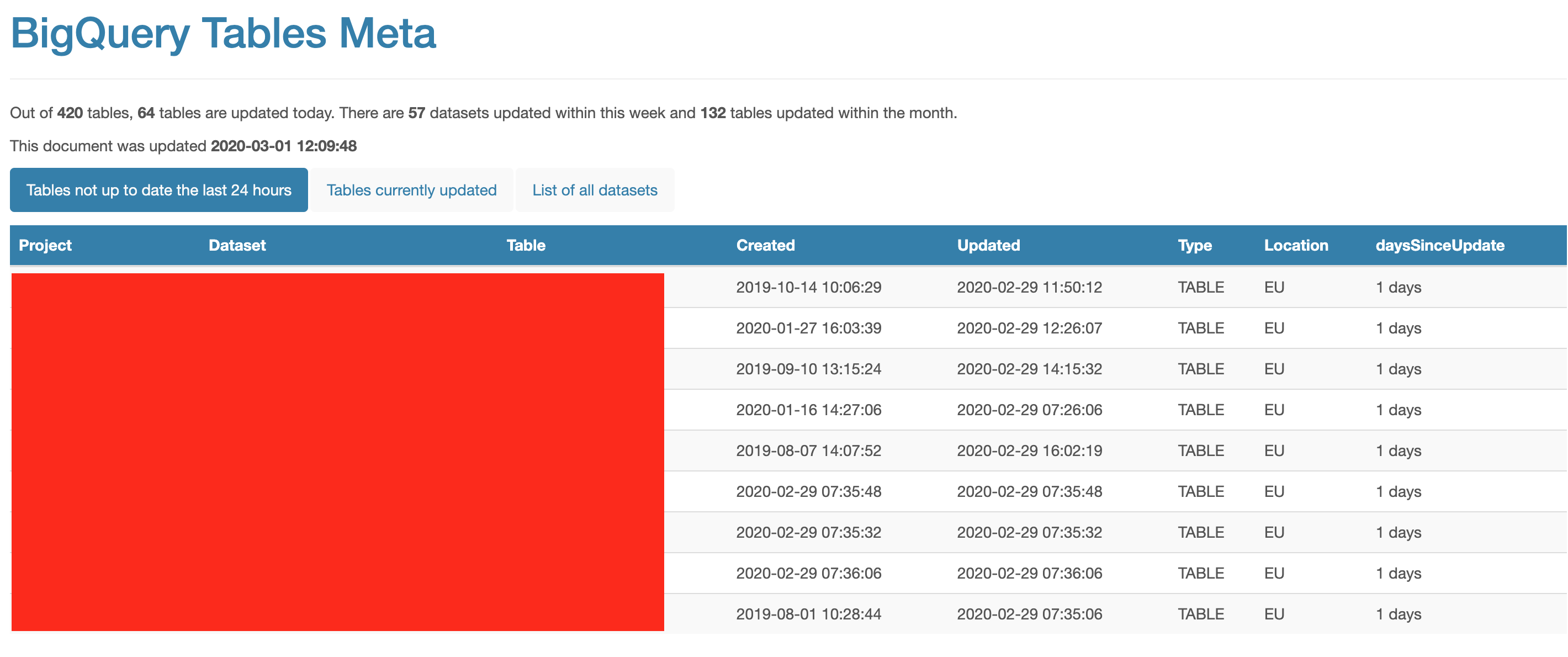
This makes it possible to see the tables who are not updated within the last day, which one who are updated, and a list of all tables. It even colors table in different colors depending on how long it has been since the last update.
Tables not updated are not nesscesarily a bad thing, as some static tables are needed to benchmark. I do however recommend to look at some of the tables once in a while to see if it would make sense to delete them.
Below is the code that I used to generate it:
Conclusion and final thoughts
This post displays a way to monitor your bigQuery tables. If you are running a lot of jobs, it can make sense to use this as a quick way to see if some tables are not updated, should some of your systems fail. For building data pipelines using cronjobs, og cloud builds etc. I do recommend take a look at Stackdriver in GCP, as it can monitor failed jobs and send textmessages, slack notifications or emails with customized dynamic text. I will try and write a guide about this in the future.
If you do consider automating grabbing the metadata from bigQuery, I recommend you to read Mark’s post on how to update it automatically using Google Cloud Build.
Let me know if this post is easy to follow or if it needs additional explanation by leaving a comment.
Danny Mawani Holmgaard
Data Engineer
I work with getting the right data into the right places, so actions can be taken from it.